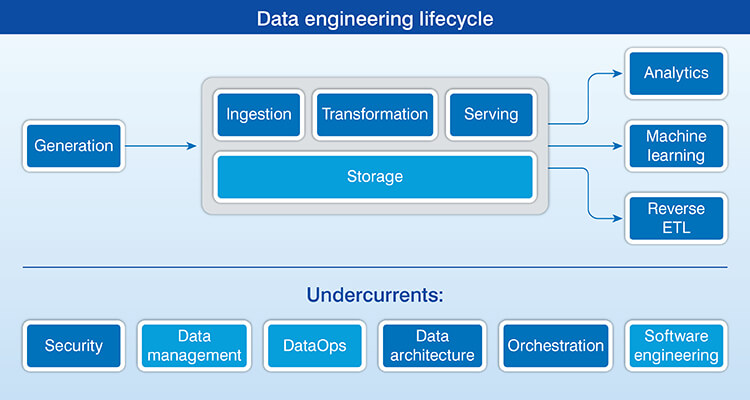
Data engineering involves architecting and structuring data pipelines for collection, processing, storing, and delivering data on a stable data platform. This allows organizations to store, process and retrieve high quality data at a speed that makes analytics useful, and AI driven.
Table of Contents
The variety of organizational data generated through different input channels such as customer touch points, operational systems, IoT connected products and external partners is seemingly endless. If left unstructured, it becomes unusable and unreliable and results in unreliable reporting and failure of analytics projects.
Data engineering provides solutions by developing and establishing systematic and reliable structures for data collection, processing and organization. It also establishes governance and reliability throughout the life cycle of the data.
Organizations leverage data engineering to glean timely and accurate insight into their business, enable scalability in their analytics and establish the foundation to develop advanced AI applications.
Turn fragmented data into a scalable, analytics-ready warehouse
Build data warehouseWhat Data Engineering Means in Today’s Data Ecosystem
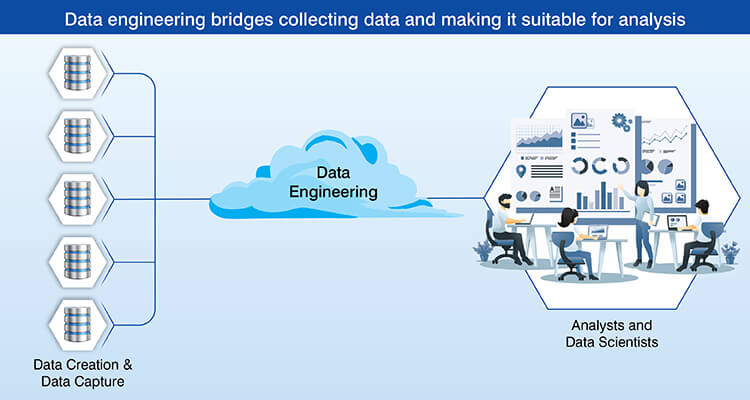
Data engineering develops and manages systems which provide a reliable, timely and correct flow of information to support decision making and analysis.
This includes all steps in the data life cycle, from data ingestion, processing, storage and delivery to end user systems. However, while data engineering creates the infrastructure used by data analysts, it does not create the analyses themselves.
The importance of data engineering is that it is the base of an analytics hierarchy. Clean, structured data are required to run analytics systems. Consistent, high quality data are also necessary to train and deploy artificial intelligence (AI) models. In order to create these systems and support them, data engineering systems must be developed first.
Core Components of Data Engineering Systems
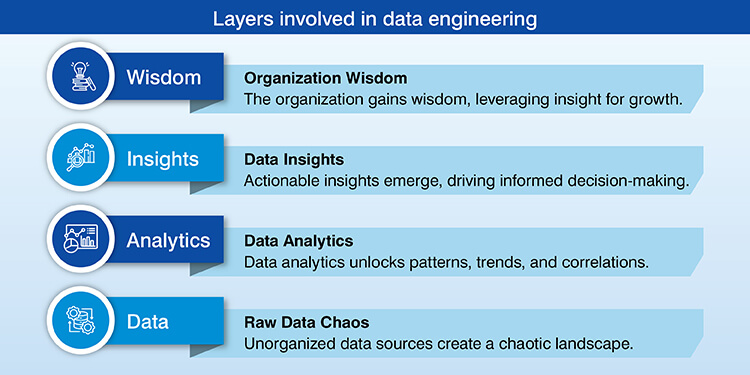
To move enterprise data from a source to consumption it is necessary to have a series of layers that will function together as a complete data engineering process.
A. Ingestion layer and source data
The enterprise data can be generated by several types of data sources including transactional databases, application logs, APIs, file systems and streaming platforms. As such, each data source will generate data in different forms, i.e., CSV files, JSON documents, database tables, real-time event streams.
| Data type | Characteristics | Examples |
|---|---|---|
| Structured | Defined schemas with typed columns | Relational database tables, CSV files |
| Semi-structured | Nested hierarchies without rigid formatting | JSON, XML documents |
| Unstructured | No predefined organization | Text files, logs, images |
There are two common methods for ingesting data into a data processing platform. One is the method of capturing the data in batches and the other is the method of continuously collecting the data from an event stream.
Reliability requires that the data will be received by the data processing platform regardless of whether there are network disruptions or the data source has failed.
B. Data pipelines and processing layer
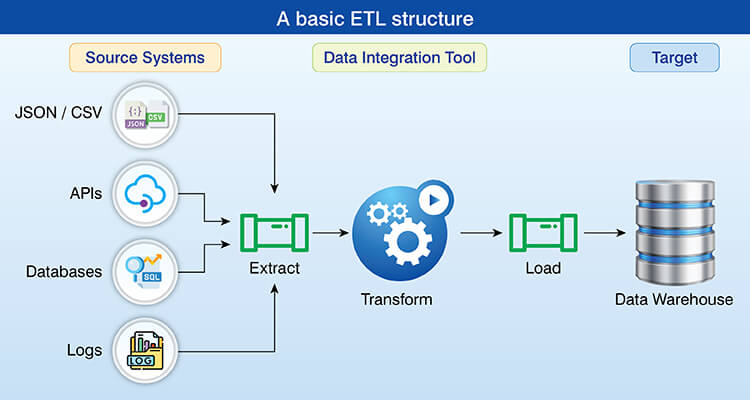
Engineering systems move and transform data through data pipelines which are engineered to efficiently automate the work that is required to collect, prepare and explore digital data to identify new insights or other useful information.
Data scientists spend 50-80% of their time collecting, transforming and preparing data before they can begin to analyze it to find useful information. So efficient automation through data pipelines is a way to reduce this manual effort.
ETL (data extraction, transformation, and loading) extracts raw data, applies business logic to transform the extracted data and finally loads transformed data into a target store for use.
Modern architectures may utilize an ELT approach, where raw data is loaded directly into scalable storage solutions, with transformations applied afterwards. This allows organizations to leverage the increased processing capabilities of data warehousing.
The business logic applied to transform raw data into processed data includes calculations, dataset joins, record filtering and standardized formatting. Data pipelines should also handle variations in data volumes, velocities, and schemas.
C. Data storage and access layer
Data warehousing is a way to store data as structured storage optimized for analytical queries. Increasing amount of it is completed in the cloud. Reports indicate that greater than 94% of enterprise organizations are using cloud-based solutions for their data workloads.
Warehouses organize data into schemas designed for reporting purposes instead of transactional operations.
Data lakes store raw and intermediate data in native formats. These can be divided based on processing stage to create clarity. Raw zones will include unaltered source data, processed zones will include cleaned records, curated zones will provide analytics ready datasets.
D. Orchestration, monitoring, and reliability layer
Pipelines are scheduled in orchestration systems by executing each stage and maintaining workflow dependency. Pipeline monitoring is continuous tracking of pipeline health, execution time, resource usage and other metrics.
There are several types of failure handling techniques to be used in pipeline management including automatic retry of transient failures and alerts for user to intervene manually. Repeatability allows users to troubleshoot confidently and conduct historical analysis.
Accelerate cloud adoption with structured data migration
Contact usData Warehousing and Data Modeling Foundations
Data warehouses are created as a single point of reference to help organizations meet their analytical needs. In contrast to the transactional databases which focus on speed of transaction, these are designed to allow for large volumes of data to be queried for the purpose of finding trends in the data.
Data modeling is how data is organized into a warehouse. This includes the structure of the data, relationships between data elements, how data will be aggregated and the indexes that can be applied to improve performance. A common approach is dimensional modeling using fact and dimension tables.
Well structured data modeling helps in data analysis faster by providing a logical way to organize the data and reduces the complexity of queries. This also allows non technical users to have access to a larger amount of data and perform tasks independent of IT personnel.
Data Warehousing for Advanced Analytics for an IoT-Focused Manufacturer

A leading IoT service provider in Asia supplying digital monitoring services to large scale manufacturers globally experienced difficulties extracting insights from their data and performing advanced analytics. They also faced platform restrictions, API limits and lack of documentation.
Hitech Analytics developed a cloud-based data warehouse using AWS Redshift as a solution to provide scalable data storage, easy access and custom reporting for advanced analytics and BI capabilities.
The end results were:
- A cloud data warehouse that had 100% uptime available 24/7
- Automated real time data pipelines for the IoT data
- Scalable pipeline to support advanced analytics
Data Engineering Tools and Technology Stack
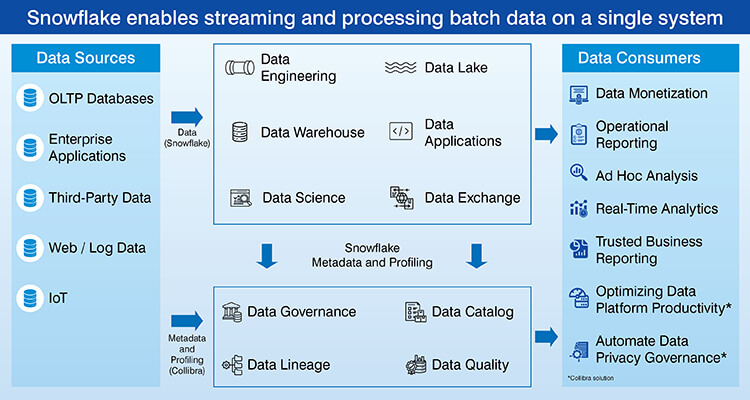
Choosing the right tool stack involves considering what technical requirements needs to be met, what capabilities your team has, what existing infrastructure you have and long term maintenance costs.
- Automated ingestion and integration: Fivetran & Airbyte automate data connectors, Apache Kafka is used for streaming ingestion, and Debezium captures change data.
- Distributed processing and transformation frameworks: Apache Spark is used for distributed batch processing, dbt for SQL-based transformations and Apache Flink in real-time stream processing.
- Workflow management and orchestration systems: Apache Airflow and Prefect helps in scheduling and dependency management.
- Data quality, monitoring, data governance: Great Expectations is used for validation Monte Carlo for observation and Collibra for governance and catalog management
The following is a chart showing the leading tools in each category and their primary application:
| Tool category | Popular tools | Primary use case |
|---|---|---|
| Data warehouses | Snowflake, BigQuery, Redshift | Centralized analytics storage |
| Processing engines | Apache Spark, dbt, Databricks | Large-scale data transformation |
| Orchestration | Apache Airflow, Prefect, Dagster | Workflow scheduling and monitoring |
| Streaming | Apache Kafka, Apache Flink, Kinesis | Real-time data ingestion and processing |
Choosing the right platform can greatly decrease overhead. For example, customers who have migrated from legacy solutions to modern platforms such as Snowflake report an average cost savings of 50-70%, primarily because of built-in optimizations.
Data quality and data governance in data engineering
Data quality is one of the most important aspects of data engineering. Quality of data can be defined by five key areas that include accuracy, completeness, consistency, timeliness and validity. A poorly designed system can result in missing fields, duplicate records, inconsistent field formats and incorrect or irrelevant information being stored in the database.
Poor data quality has real financial implications on your organization. According to Gartner, organizations lose an estimated $12.9 million per year due to poor data quality.
You need to validation against bad data as you transition between each step in your pipeline. Monitoring data quality with continuous tracking allows you to measure performance metrics such as null rate and duplicate percentage. Testing verifies the transformation logic to confirm that the output will always produce the expected results.
Data governance refers to establishing policies regarding how data will be managed and used. This includes establishing who may have access to specific data sets, the way in which this data should be utilized and compliance to regulations and laws governing data collection, use and storage.
Data Engineering Tips and Best Practices
Follow best practices so your data pipeline is scalable, reliable and easy to manage across all the changes your system will go through.
Tip 1: Design data pipelines for scalability from the start
If you are building a pipeline based on anticipated volume of data and it grows exponentially within you can avoid having to rebuild at scale. Don’t embed any form of hard coded logic into your pipeline such as embedded database connections, file paths or transformation rules. If you do then you will have to modify your pipeline for each environment.
Build modular components that allow for reuse in multiple work flows. A well designed extraction module can work for any type of database source. The generic transformation functions can also work for multiple types of data sets.
Support both batch and incremental processing. In some cases there will be full refresh requirements while other cases will be efficiently updating based on only those records that have been modified.
Tip 2: Prioritize data quality at every pipeline stage
Validate data early on during ingestion to find problems quickly. Validate your schema to ensure you have all the necessary fields and they are in the right format. Use range checks to confirm the value falls in a valid range.
Plan for missing values, duplicates and varying formats. Missing critical fields might mean rejecting the record. Ingestion is where it is most important to address these because nearly 47% of new records created by an organization contain at least one critical error that will negatively affect down the line if not addressed here.
Use quality check processes before sending the data downstream to be used by others as a last check. This can confirm that the aggregation includes the expected number of records.
Tip 3: Build reliable pipelines with monitoring and recovery
Track the status of your data pipeline through a dashboard to monitor its overall health. Trends in historical data allow you to identify declining performance before it causes a complete failure.
Retry logic is implemented for transient error conditions. If a network glitch occurs retry logic will attempt to run failed operations again after a short delay using an exponential back off strategy.
Workflows are designed to be idempotent so that if they need to be run multiple times they will produce the same result each time. In restart safe work flows when a checkpoint has been established, the workflow will resume at the checkpoint instead of having to process everything over again.
Tip 4: Apply clear data modeling and naming standards
Organize your data with an analytics focus. Fact tables provide quantifiable data regarding activities or events that are connected to dimension tables which describe the characteristics of the event. By organizing your data based on the business case you want to analyze as opposed to how it was structured when it came from its source, the usability will improve.
Use a standard for all naming conventions. The name of the table clearly states what is contained within and why. Column names consistently reflect the structure of the data and date fields have ‘date’ in their name.
Tip 5: Document and govern data engineering workflows
Data pipelines and transformations are documented along with assumptions in order to develop institutional knowledge. Documentation helps explain the reasoning behind a transformation’s logic and how edge cases have been addressed.
Documenting DATA LINEAGE allows tracking of the data from source to transformation to consumer. Data Lineage allows for understanding which reports are dependent upon which pipelines therefore it is easier to determine the potential impacts prior to making any modifications to the pipeline.
Documentation also supports data governance and compliance requirements by providing an audit trail of how sensitive data has been processed. Providing documentation regarding retention policies proves regulatory compliance. This helps support better collaboration among teams.
Conclusion
The strength of an organization’s data engineering capabilities will ultimately decide if they can effectively utilize their data asset base or continue to deal with uncertainty regarding the accuracy of their data.
Well-built systems with structured data pipelines, data quality assurance and control processes provide analytics teams and AI initiatives with a platform for delivering consistent value.
Ultimately, the business benefit is through better, more timely decision making and higher confidence in the insights being generated. Organizations who invest in strong data engineering practices are positioning themselves for long-term success as a data driven enterprise.
Strengthen decision-making with a robust data strategy
Talk to an advisor
At Hitech Analytics, we understand that each company has different needs, business goals and technology environments. With advanced analytics, you can make right decisions, prepare for the future and leverage intelligence from huge data volumes. We embed analytical intelligence into your everyday data and turn it into actionable insights.