Data pipelines are automated processes that move data and allow you to reliably deliver data to multiple destinations for real time analysis or do batch processing. Data pipelines also make it easier to collect, process and deliver accurate data at scale across industries.
Table of Contents
- What is a data pipeline in modern data systems
- Core components of a data pipeline architecture
- How data pipelines process and move data
- Understanding different types of data pipelines
- Key benefits of using data pipelines
- Common data pipeline use cases across industries
- Challenges in managing data pipelines at scale and their solutions
- Conclusion
Every day, organizations are creating large amounts of data across all their applications, databases and other systems. This is part of an increasing global trend with the projected creation of 463 exabytes of data per day by 2025. As such manual processing is no longer viable.
Automated data pipelines provide reliable frameworks for extracting, processing and delivering data from many different sources to a variety of analytical destinations. By providing repeatable work flows these systems ensure consistent delivery while decreasing the need for manual intervention.
Robust pipeline architecture provides rapid analytics, higher quality analytics and scalable operations for business intelligence and machine learning applications.
What is a data pipeline in modern data systems
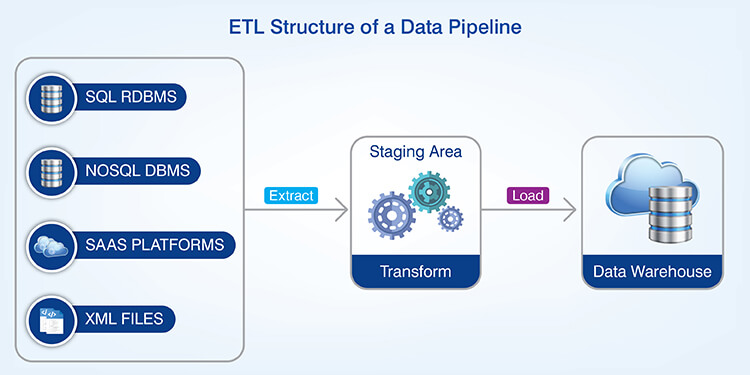
Automated systems using workflow orchestration to move data between different locations, apply transformation to the data and deliver it to be used by analysts for decision-making and for operational use. These types of systems are called data pipelines.
The primary characteristics distinguishing a data pipeline from a simple transfer include automation, repeatability, execution of a predefined workflow based upon a schedule or trigger, application of standard rules and systematic error management.
In terms of reliability the stakes are high, as indicated by Gartner research, which states that poor data quality results in an average loss of $12.9 million per year for each organization.
Production data pipelines must provide failure, interruption and quality error resolution without data loss. Modern data pipelines are designed with continuous monitoring capabilities that detect failures and automatically recover from them.
Data pipelines act as a backbone to connect operational systems to analytical environments and enable the consolidation of distributed information.
| Aspect | Basic data transfers | Data pipelines |
|---|---|---|
| Data pipelines | Manual or semi-automated | Fully automated workflows |
| Transformation | Minimal processing | Comprehensive validation and transformation |
| Reliability | Limited error handling | Automated monitoring and recovery |
| Repeatability | Inconsistent execution | Scheduled, consistent processing |
Build scalable data pipelines for faster, reliable business insights
Build data pipelinesCore components of a data pipeline architecture
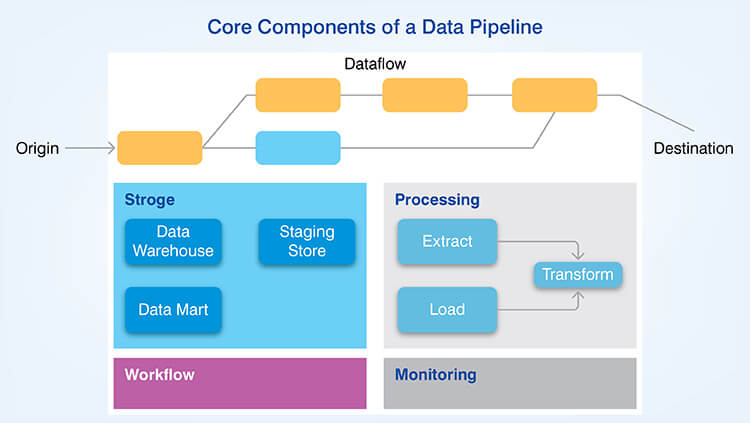
The complete architecture of a data pipeline is comprised of five connected layers that manage the lifecycle of data from its generation or creation all the way to its use by consumers of data.
A. Data sources
Structured, semi-structured and unstructured data is generated by operational databases, applications, APIs, logs and event streams. These data sources can include relational databases, NoSQL databases, Internet of Things (IoT) devices, and click-stream data. The volume of data generated by these data sources is tremendous. It is estimated there will be over 39 billion connected IoT devices by 2030.
B. Data ingestion layer
The batch processing component of the data ingestion layer captures data at fixed time intervals and the streaming pipelines continuously captures events for near real-time analytics. This layer provides variable arrival rates of data using buffers and adaptively processes data.
C. Data processing and transformation layer
Incoming data received by the data ingestion layer is cleaned and transformed into usable information, which removes duplicate records and corrects errors or discrepancies. While data transformation, business logic is applied to calculate values and add enrichment data as needed. Finally, schema alignment is performed to map the structure of the source data to the desired format of the target data.
D. Data storage and serving layer
Raw, unprocessed data is stored in native formats in data lakes for exploratory analytics. Structured, pre-aggregated and ready-to-use data is stored in data warehouses for high-performance queries. The global data warehousing market is expected to explosively grow over $39 billion by 2032. Downstream systems consume processed data via APIs, database connections, etc.
E. Pipeline management and monitoring
Pipeline scheduling determines the order in which the tasks should be executed. Pipeline monitoring tracks the progress of each task and provides metrics and alerts if a task fails. Finally, pipeline error handling includes retry logic and maintains lineage information.
Below are the primary functions of the five core components of the data pipeline:
| Component | Primary function | Key technologies |
|---|---|---|
| Sources | Data generation | Databases, APIs, event streams |
| Ingestion | Data capture | Batch schedulers, streaming platforms |
| Processing | Transformation | ETL/ELT engines, validation frameworks |
| Storage | Data persistence | Data lakes, warehouses |
| Management | Orchestration | Schedulers, monitoring tools |
How data pipelines process and move data
Sequential processes are used in a data pipeline to direct data from creation to usage with transformation and quality control.
Step 1. Data creation: Source systems generate data as a result of transactions or events. Change capture techniques track which records have changed to be captured.
Step 2. Data ingestion: Pull based methods include querying source systems at periodic intervals, push based methods involve receiving streams of published changes to your system. Batch processing performs large scale operations on bulk data and real-time data ingestion performs data collection as it happens.
Step 3. Validation: Validating schema determines that the data conforms to the defined structure. Complete validation identifies missing fields. Duplicate validation eliminates duplicate entries in order to ensure data accuracy.
Step 4. Transformation: As part of the ETL process data is extracted from its original format, transformed into another format and loaded into a data warehouse or data lake. Calculations and enrichment are applied based upon business rules.
Step 5. Loading: Data is written to data warehouses and data lakes by transforming operations. Data is stored most efficiently using partitioning and compression.
Step 6. Consumption: The final step in a data pipeline is when datasets can be consumed for analytics, reporting and machine learning via business intelligence applications and APIs.
Understanding different types of data pipelines
Each organization chooses a type of data pipeline architecture based upon their velocity needs and how much time they are willing to spend waiting for data.
A batch pipeline runs on a schedule, processes large amounts of data collected together and executed as part of a single event. It makes sense when an application can tolerate some delay in receiving its data. It also allows for maximum use of resources.
Streaming pipelines processes data continuously as each new event occurs and provides nearly immediate availability. It is best suited for high velocity sources such as IoT devices and financial transactions where minimum latency is required.
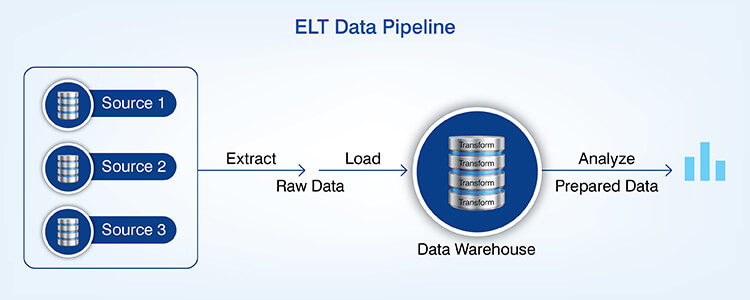
An ETL process pipeline extracts data, performs transformations and loads the result. The three tasks occur in separate environments allowing for the creation of very complex logic.
An ELT process pipeline first loads raw data into a target and then executes any necessary transformations via the processing capability of the target. Since over 60% of all corporate data is now stored in the cloud, ELT uses cloud warehouse processing capabilities.
Hybrid architectures include both batch and stream components, which allow organizations to strike a balance between low latency and high efficiency. Organization may choose to stream data to support mission critical real time applications and use batches to analyze historical data.
Key benefits of using data pipelines
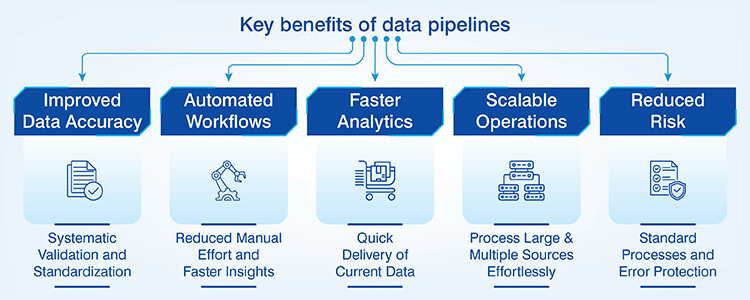
Implementation of a data pipeline benefits an organization in both operational and analytical areas affecting business performance.
- Data accuracy improvement: Elimination of manual entry errors such as data format discrepancies and missing updates through systematic validation and standardized transformation improves the reliability of data.
- Automation of workflows: Automation of repetitive tasks through scheduled execution reduces resource utilization for higher level analytical work while reducing the time required for insight development for all stakeholders.
- Speed of analytics: Quick delivery of reliable and timely data ensures that stakeholders have access to the most current data when they need it. This also ensures that the dashboards remain current through the predictability of updates.
- Ability to scale: The ability of pipelines to process large amounts of data as well as multiple additional data sources with no increase in proportionate effort through the use of distributed processing enables organizations to scale their operations.
- Reducing risk: The implementation of standard processes, comprehensive monitoring capabilities and automation of error handling processes provides organizations with the protection against data loss enabling business continuity.
Eliminate data silos with secure, end-to-end pipeline development
Talk to our expertsCommon data pipeline use cases across industries
The data pipeline supports a multitude of analytical and operational use cases across many industry sectors including finance, healthcare, retail, manufacturing and technology.
Business intelligence and reporting
Scheduled dashboard refresh pipelines provide automated execution of updated dashboards that allow users to view their metrics in real time. Data pipelines support the ability to report on KPIs as well as ensure that reports reflect the most up-to-date performance of an organization’s operations through predictable cycles.
Data warehousing and analytics
Pipelines combine information from various sources into one location that is data warehouses, allowing for centralized access to all information from an organization. Long term historical trending can be analyzed when data is consistently delivered over long periods of time, thus providing patterns and predicting capabilities. Demand for this capability is increasing rapidly as the predictive analytics market is projected to increase at least 28% per year until 2030.
Real-time analysis and monitoring
Real time streaming pipelines continuously collect metrics and immediately alert stakeholders about anomalies or opportunities to respond to changing conditions. Real-time data processing allows organizations to detect anomalies and respond to time sensitive opportunities.
Machine learning and advanced analytics
Pipelines that deliver validated training dataset to machine learning models enable developing models based on the most accurate and reliable data possible. Inference pipelines provide models with current feature data that ensure the accuracy of predictions made by the models.
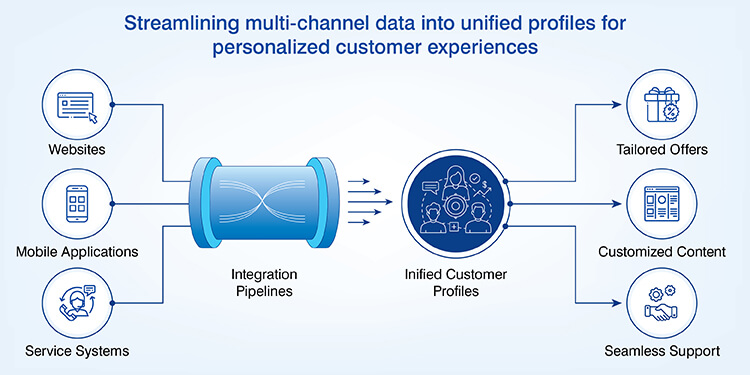
Customer data integration
Pipelines that integrate customer interactions across websites, mobile applications and service systems create unified profiles of customers across multiple channels. The integration of these systems support personalized experiences for each customer.
Data migration and modernization
Pipelines support organizations moving their legacy systems to cloud platforms in a systematic manner and transfer all historical data to the new platform. These pipelines provide the necessary validation to ensure the integrity of data as it moves from legacy systems to new cloud based systems so that legacy systems can be decommissioned while preserving all critical data.
Real-Time Lead Scoring Model for a USA-Based Tech Company

A U.S.based integrated technology services firm was experiencing unstructured lead flows into their organization through a variety of channels making it difficult for them to evaluate or prioritize these leads. The organization wasted time qualifying many low value leads.
Hitech Analytics created an algorithmic lead scoring model using keywords to standardize and clean data as well as assess other important attributes such as location and company size. The model then scored each lead based on its priority level and directed the highest priority leads to sales team members.
The end results were:
- 50% increase in sales rep productivity
- 200% improvement in MQL to SQL conversion
- Faster closings and strengthening revenue pipeline
Challenges in managing data pipelines at scale and their solutions
Companies with large scale production data pipeline infrastructure experience a number of issues that can be solved by implementing methodical processes to maintain both the dependability and performance of their infrastructure.
Schema drift and poor quality data
- Challenge: Poorly formatted and changing schema cause problems during integration.
- Solution: Validation rules help to ensure all data meets standards for the application. Schema enforcement tools can identify when structural or logical changes have been made to the schema.
Pipeline failures, component dependencies
- Challenge: A failure upstream in the pipeline causes a failure in the downstream systems due to the cascading nature of the pipeline.
- Solution: Component decoupling will isolate them from each other so if one fails it will not affect the others. Retries may also be used to automate recovery of failed components.
Gaps in monitoring and observability
- Challenge:Lack of visibility into the operations of the pipeline will cause delay in identifying the problem and resolving it.
- Solution:There is centralized monitoring that collects and reports on the health of the pipeline. Alerts will notify the team as soon as there is an issue.
Constraints related to scalability and performance
- Challenge: As the volume of data increases the infrastructure becomes overwhelmed which results in delays.
- Solution: Data will be processed in a distributed manner (horizontal scaling) and data will be partitioned and processed in parallel.
Increasing cost, inefficient operation
- Challenge: The increased cost of the infrastructure puts pressure on budgets.
- Solution: Data will be processed in a way that is optimized to reduce computational overhead, and data will be stored based on its life cycle. This means that less frequently accessed data will be archived.
Conclusion
Modern businesses depend on data pipelines to build a strong foundation of data driven decision making and reliable analytics. Choosing appropriate data pipeline types based on latency requirements and transformation complexity will help ensure that your systems are both useful and sustainable.
By developing a strong architecture, organizations can use their data pipelines as a competitive advantage by providing faster insights, better quality data and scalable operations to support today’s business needs and tomorrow’s initiatives in machine learning and real time optimization.
Turn fragmented data sources into a unified analytics pipeline
Contact us
At Hitech Analytics, we understand that each company has different needs, business goals and technology environments. With advanced analytics, you can make right decisions, prepare for the future and leverage intelligence from huge data volumes. We embed analytical intelligence into your everyday data and turn it into actionable insights.